1分钟了解手游性能优化(3)——GPU渲染架构之IMR
在上一篇文章中,我们简单地了解到了PC端与移动端硬件的差别。在这篇文章中,我们了解PC端常用的渲染架构Immediately Mode Rendering(IMR)。

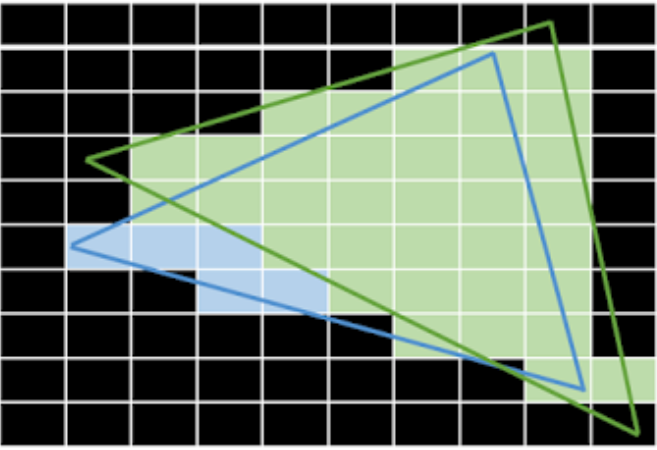
顾名思义,IMR就是立即渲染模式。如上图所示。Drawcall 1 是渲染蓝色三角形。Drawcall 2 是渲染绿色三角形。简单地说,GPU 在收到渲染指令后会立即执行。首先会处理Drawcall 1, 绘制蓝色三角形。经过顶点着色器和片元着色器阶段后,会把绘制数据直接写到位于VDRAM上的Frame Buffer。然后执行Drawcall 2,以此类推。
再更细致地了解这个过程,如下图所示。

以执行Drawcall 1 为例, GPU首先会从VDRAM上提取Triangle A的顶点数据(Vertex Data)。然后进行坐标变换,裁剪,屏幕映射等阶段后,会进入到光栅化阶段(Rasterization)。
光栅化阶段会把上面阶段得到的几何数据(Geometry Data) 转为成片元(fragment)并内插出逐片段(per-fragment)所需要的相关属性(深度,颜色,纹理坐标等)。现在大部分GPU支持early depth testing(提前深度测试)。这是一种硬件特性,允许在片元这色器执行前进行深度测试,如果某个片元是不可见的,则丢弃它,以减少片元着色的工作量。
进入Fragment processing阶段,每个片元会从VDRAM中提取纹理数据(texture data)并进行shader计算。如果片元着色器会调整深度,则下一步会进行Later depth testing,这里可能会再读写Depth Buffer。
最后会进入到渲染输出单元(Render Output Unit),是渲染过程的最后步骤。如果需要进行混合,则还需要从VDRAM中读取FrameBuffer,进行alpha混合后再写回到DRAM。
下图是处理完Drawcall 1后,Frame Buffer中的内容。

接着GPU以相同的流程处理Drawcall 2。假设Triangle B 的每个fragment的depth都是小于Triangle A的,则处理完Drawcall 2后,Frame Buffer中的内容如下图所示:
从上述描述可知,由于每次Darwcall 都会把渲染结果写到Frame Buffer上,过程中也涉及到比较多的数据交换(Vertex Data, Texture Data等),因此有比较高的带宽要求及功耗要求。
参考: