AWS Serverless搭建Tensorflow/TFlite推理服务

为什么要使用Serverless进行机器学习推理
无服务器架构(Serverless architecture)有一些众所周知的优点:
人力成本:使用无服务器架构可以节省服务器硬件和维护成本。开发人员毋需担心服务器管理和扩展问题。
硬件成本:无服务器架构允许应用程序在不使用时自动停止运行,这可以帮助减少资源浪费。若请求时间是离散的,它比24小时不停运行的服务要便宜得多。
自动扩容:无服务器架构允许应用程序随着流量的增加而扩展。
因此,把一些使用频次不高的机器学习推理应用部署在Serverless上,是一件值得尝试的事情。
使用Serverless部署机器学习推理应用的挑战
然而要在Serverless上部署机器学习推理应用不是一件十分容易的事情,你可能会面临以下问题:
部署依赖包:机器学习经常会用到一些包含c/c++语言的包,如numpy、scipy、pandas、sklearn、tensorflow等。这些依赖库的依赖项(如glibc)未必与serverless运行时的环境吻合。
部署大小限制:以AWS为例,部署的总包的大小不能大于250MB。
冷启动问题:当服务长时间不使用时,虚拟机和容器会被关闭,以节省资源。因此,第一次调用时,需要重新启动虚拟机和容器,这个过程可能长达数秒甚至数十秒。
所幸,serveless如今支持基于docker镜像的部署方式,可以一定程度上解决1,2的问题。而通过并发预置或者定时调用的方案,也可以一定程度上缓解3的问题。
实战1:利用SAM CLI在AWS Lambda上部署tensorflow
SAM(AWS 无服务器应用程序模型)是一个用于构建Serverless应用的开源框架。它为我们提供了很多常用的AWS Lambda Serverless模版,当中包含用于机器学习应用的模版。
首先让我们下载SAM CLI。
SAM CLI 是SAM的命令行工具。这个工具提供类似于 Lambda 的执行环境,让我们可以在本地构建、测试和调试由 SAM 模板或通过 AWS 云开发工具包 (CDK) 定义的应用程序。我们还可以使用 SAM CLI 将我们的应用程序部署到 AWS。
安装好SAM CLI之后,可以通过sam init 命令进行Serverless 应用的初始化工作。具体流程如下:
通过命令行工具进入一个空目录之后
- 输入sam init ,选择"AWS Quick Start Templates"
- 询问选择的模版,选择"Machine Learning"
- 询问使用的python版本的,选择"python3.9"
Select your starter template
1 - PyTorch Machine Learning Inference API
2 - Scikit-learn Machine Learning Inference API
3 - Tensorflow Machine Learning Inference API
4 - XGBoost Machine Learning Inference API
- SAM Machine Learning Template目前提供了基于Pytorch,Scikit learn,Tensorflow,XGBoost四个starter 模版。
最后会让我们选择是否开启 X-Ray tracing以及填写应用的名称。X-Ray tracing用于跟踪应用的全链路性能状况。这里我们选择N。应用名称使用默认的sam-app。
成功后我们将会看到如下信息:

并有如下的目录结构:
- app/app.py - 包含机器学习程序的Lambda应用程序代码。是Lambda的云函数入口。
- app/Dockerfile - 用于构建容器镜像的 Dockerfile。
- app/model - 基于 MNIST 数据集训练的用于分类手写数字的简单 Tensorflow 模型。
- app/requirements.txt - 容器构建期间需要安装的pip依赖。
- events - 用于调用函数的调用事件,用于测试。
- template.yaml - 定义应用程序的 AWS 资源的模板。
- training.ipynb - jupyter 笔记本,显示 app/model 中的示例模型的训练过程。
可知这是一个用于分类手写数字的机器学习推理应用,查看Dockerfile可以看到它的构建过程:
FROM public.ecr.aws/lambda/python:3.8
COPY app.py requirements.txt ./
COPY model /opt/ml/model
RUN python3.8 -m pip install -r requirements.txt -t .
CMD ["app.lambda_handler"]
镜像引用的是lambda python3.8的运行环境。再看看python的依赖项requirements.txt:
tensorflow==2.9.3
pillow==9.3.0
使用的是tensorflow 2.9.3版本。
接下来我们构建镜像:
在sam-app 目录下,执行sam build命令会进行镜像构建,当然前提是你安装并启动了docker,不然会出现如下错误:
Build Failed
Error: Building image for InferenceFunction requires Docker. is Docker running?
由于tensorflow2.x 体积比较大,构建需要较长的时间。构建完成后,在docker Desktop中可以看到:

镜像已经被构建出来了,大小约为2.58GB,当中模型的大小只占1.7MB。
通过命令:
sam local invoke -e events/event.json
将会进行本地测试:
{"statusCode": 200, "body": "{\"predicted_label\": 3}"}
其中event.json文件包含了用于分类的图片Base64数据。可以看到分类任务被顺利执行。
此时通过sam deploy --guided命令,可以将镜像上传到AWS,并选择是否部署Lambda云函数。
然而由于镜像比较大,云函数冷启动时可能需要比较久的时间,甚至发生错误。基于以下条件进行测试:
模型大小:217.3M
依赖:
tensorflow==2.9.3
pillow==9.3.0
bchlib>=0.7
此时本地镜像文件高达3.33GB,上传到aws后,也有1743.41MB。
冷启动时会出现如下错误:
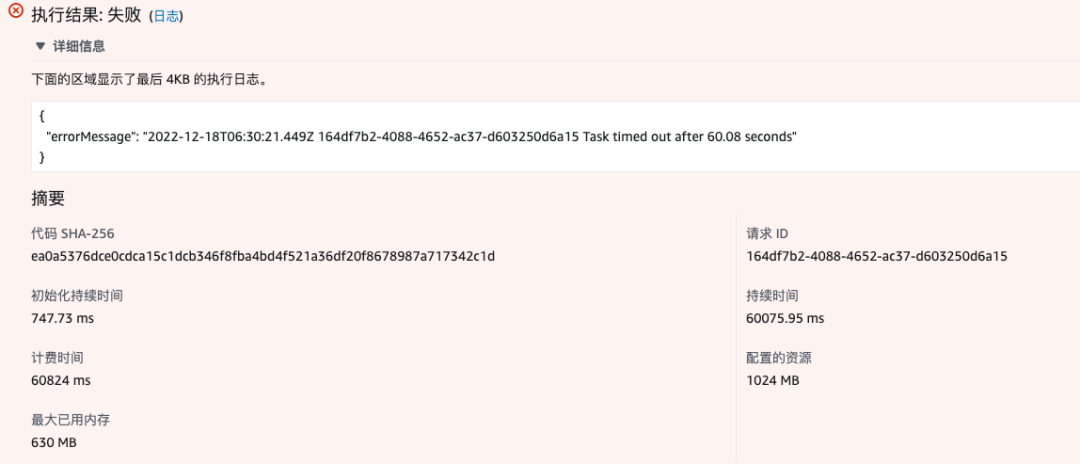
冷启动之后再次执行则运行正常。
虽然冷启动之后能正常运行,但有些时候冷启动时难以避免的,因此我们希望尽量减少镜像的大小以及运行所需要的资源(如内存,模型大小)。
考虑到我们要进行的是推理服务,并不需要训练等相关模块,因此我们可以使用TFLite来进行推理,而不是安装全量的tensorflow。
实战2:在AWS Lambda上部署TFLite应用
TensorFlow Lite 是 TensorFlow 移动和嵌入式设备轻量级解决方案。它具有低延迟和更小的二进制体积的特点。
要在AWS Lambda上部署TFLite应用,需要在实战1的基础上稍作修改
1.使用TensorFlow Lite替换tensorflow
2.把已有模型转换成TFLite可用的模型
修改requirements.txt文件如下:
pillow==9.0.1
tflite-runtime==2.7.0
bchlib>=0.7
这里需要指定tflite-runtime版本为2.7.0,否则会报如下错误:
ImportError: /usr/lib64/libm.so.6: version `GLIBC_2.27' not found
用tflite替换tensorflow模块后,推理的API也要做响应修改:
import tflite_runtime.interpreter as tflite
interpreter = tflite.Interpreter(model_path="./model.tflite")
interpreter.allocate_tensors()
signatures = interpreter.get_signature_list()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()[0]
timestamp = time.time()
interpreter.set_tensor(input_details[0]['index'], image)
interpreter.invoke()
print('comsume time: ', time.time() - timestamp)
output_data = interpreter.get_tensor(output_details['index'])[0]
具体关于TFLite推理API的说明,可以参考这个链接。
接下来要进行模型转换,把tensorflow训练的模型转为tflite可使用的模型:

这里以转换我手上的tensorflow 1.x 输出的SavedModel为例:
import tensorflow as tf
# Convert the model.
converter = tf.compat.v1.lite.TFLiteConverter.from_saved_model('saved_models/stegastamp_pretrained')
tflite_model = converter.convert()
# Save the model.
with open('model.tflite', 'wb') as f:
f.write(tflite_model)
修改完毕后,再运行sam build命令重新构建镜像,可以看到此时本地的镜像大小为1.39GB。与全量安装tensorflow相比,减少了近2GB。推送到AWS后,镜像大小为628.57MB。
在lambda中替换刚才构建推送的镜像进行测试,此时冷启动阶段运行耗时30.37秒,其中耗费在推理的时间为24.33秒。非冷启动情况下,运行时长2.85秒,推理时间2.81秒。
虽然结果仍然不让人满意,但冷启动阶段相比使用全量的tensorflow,至少没有报错了。
我们试着进一步对镜像体积进行优化,接下来我们优化模型的大小。在这里我们使用TFLite的训练后量化工具—动态范围量化。
根据官方文档描述,优化后,模型大小可缩减至原来的四分之一,速度加快 2-3 倍。优化模型代码如下:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
converter = tf.lite.TFLiteConverter.from_saved_model('saved_models/stegastamp_pretrained')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_model = converter.convert()
# Save the model.
with open('tflite_quant_model.tflite', 'wb') as f:
f.write(tflite_quant_model)
print('Save the model.')
此时模型大小由原来的219MB减少到56.3MB。镜像由原来的1.39GB减少到1.23GB。推送到AWS后,镜像由原来的628.57MB缩小到450.54MB。
再次运行云函数测试,出人意料地,冷启动超时了。非冷启动运行推理的时间长达57.3秒。
为什么模型优化后,推理时间反而更长了呢?这可能是TFLite还未在x86平台完成优化的原因,那么在arm64架构上是否会有更好的效果呢?
实战3:ARM64架构下部署TFLite应用
要在AWS Lambda ARM64架构下部署TFLite应用是一个不小的挑战。首先我们修改基础镜像为ARM64,打开Dockerfile文件,把基础镜像的引用为:
FROM public.ecr.aws/lambda/python:3.8-arm64
在这个链接可以看到更多的AWS Lambda 基础镜像。
修改requirements.txt文件,去掉tflite-runtime的依赖。因为tflite-runtime将由我们自己构建的whl安装包来安装。
官方文档 提到了使用Docker进行ARM交叉编译的方式。应该是最有效率的。不过笔者没有尝试这种方式。本片文章采用的是直接编译的方。
直接编译整个流程可以归纳为:
准备与AWS Lambda 相同的python3.8 ARM64运行环境。本文使用AWS EC2 创建了一个Amazon Linux 2 LTS Arm64 Kernel 5.10环境。
安装gcc,将gcc升级到10以上。此处提到了能用的最低gcc的版本。本文使用的版本是10.2.0。
安装cmake,并将cmake升级到3.16以上。
安装Bazel作为whl的构建工具。本文用的是5.4.0的ARM64版本。
sudo curl -L https://github.com/bazelbuild/bazel/releases/download/5.4.0/bazel-5.4.0-linux-arm64 -o /usr/bin/bazel && chmod +x /usr/bin/bazel
5.git clone tensorflow的工程,并根据的说明,安装相关python依赖并执行:
sudo sh tensorflow/lite/tools/pip_package/build_pip_package_with_cmake.sh
如果你只知道一些依赖包在x86下的包名,而不知道在ARM64下的包名,可以通过yum search x86的包名进行查询,一般可以找到对应的ARM64下的包名。
如果编译顺利,最终可以获得一个tflite_runtime-2.11.0-cp38-cp38-linux_aarch64.whl文件。
回到dockerfile文件,通过whl文件安装tflite-runtime:
FROM public.ecr.aws/lambda/python:3.8-arm64
...
COPY tflite_runtime-2.11.0-cp38-cp38-linux_aarch64.whl ./
RUN pip3 install tflite_runtime-2.11.0-cp38-cp38-linux_aarch64.whl
这样就成功在AWS Lambda python3.8 ARM64架构上搭建好tflite的运行环境。
通过sam build构建镜像,使用实践2中得到的动态范围量化优化后的模型,此时本地镜像大小为1.23GB,上传到AWS后镜像大小为405.32MB,比x86_64架构下的还小了约50MB。
在云函数上进行测试:

冷启动阶段运行时间持续4.42秒,其中推理耗时为2.24秒。非冷启动阶段,运行时长1.70秒,其中推理耗时为1.66秒。
与上文的其它方案对比,此方案有了长足的提升,冷启动时长也不再那么令人难以接受。配合定时调度的方式定时触发云函数,以免我们满足日常需求的推理应用进入冷启动,这种方案已经可以在生产环境上应用了。
总结
各方案对比:
| 方案 | AWS镜像Size | 冷启动时长 | 运行时长 | 占用内存 |
|---|---|---|---|---|
| X86_64tf | 1743.41MB | 超时 | - | - |
| X86_64tflite | 628.57MB | 30.37s | 2.85s | 391MB |
| X86_64tflite动态范围量化 | 450.54MB | 超时 | 57.3s | 363MB |
| ARM64tflite动态范围量化 | 405.32MB | 4.42s | 1.70s | 469MB |
引用
[1]: Serving machine learning models with AWS Lambda
[2]: TensorFlow Lite 转换器